
May 09, 2025
Here is a quick recap of the evolution of the data world, and what the biggest shifts were.
Early Days (<1970/1980)
Databases began as simple files storing data. This had some limitations, and as the usage of technology grew, an alternative started to emerge.
Relational Databases (1970/1980)
- Specialized software, called Database Management Systems (DBMS), emerged to manage multiple tables and queries.
- Introduced structured data storage with relationships between tables.
- Database servers could manage multiple databases and tables.
- SQL became the standard query language, though dialects vary.
- Indexes, essentially metadata tables, improved retrieval efficiency.
- DBMS are known as SGBD in French (Système de gestion de base de données).
Normalization
- Normalization defined best practices for organizing data.
- Normalization detail
- Between the ’70s and ’80s, several additive best practices were identified.
- Object-Relational Mapping (ORM) tools abstracted database interactions but didn’t replace SQL.
Business Intelligence (1990/2000)
- BI focused on improving decision-making with reporting, KPIs, dashboards, and analytics.
- Dimensional modeling, popularized by Kimball, simplified data representation for business use.
- Built around facts and traits. Dimensional modeling
- While it’s old, it’s still commonly used.
- Other data modeling techniques include the data vault.
- BI queries started becoming resource-intensive for databases.
Big Data Era (2010/2020)
Companies generated data at scales too large to be manipulated using single servers (we’re talking at least GB or even TB).
Distributed computing frameworks like MapReduce and Spark emerged.
- Tasks like finding unique values or sorting were split across server clusters. For example:
- To find unique values in a big table, you split it, send the parts to several servers, each server processes its part, and finally, you regroup all the sublists and remove duplicates.
- Sorting a big table follows a similar process.
- A big framework in big data was MapReduce, which splits a big list into smaller lists, performs an action on each part (map), and finally processes the results (reduce).
- Common frameworks include Spark and MapReduce.
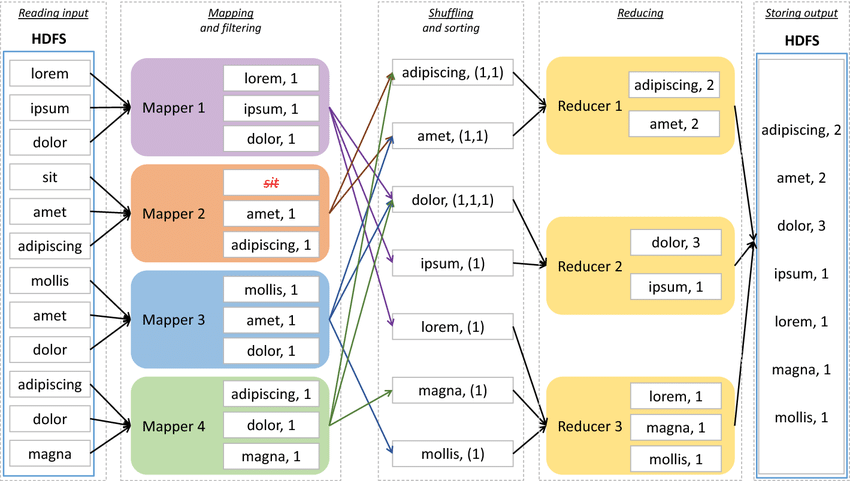 Word count using the MapReduce framework
Word count using the MapReduce framework
- CAP theorem highlighted trade-offs between consistency, availability, and partition tolerance.
- CAP theorem is becoming less relevant due to the scale we can now reach.
- Moore’s law is contested but still partly true, and computing continually becomes more efficient.
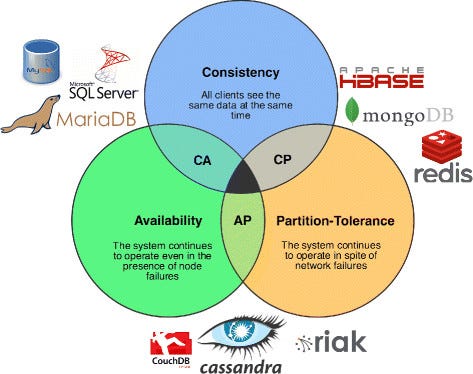 CAP Theorem highlights trade-offs between different technologies.
CAP Theorem highlights trade-offs between different technologies.
Globally, Big Data’s complexity limited its adoption for smaller-scale use cases.
Zero Interest Rate Period
Between 2015 and 2020, the FED led a ZIRP, which made acquiring money for companies fairly easy. This greatly impacted the world of data.
Big Data was seen as a way to make money. We saw phrases like “data is the new oil” and data jobs are the sexiest. Every big company wanted data scientists to turn their data into gold.
We saw some data pure players emerge:
- Snowflake (2012 - $3.3Bn revenue - $53Bn valuation)
- Databricks (2013 - $1.6Bn revenue - $62Bn valuation)
- Built by Spark contributors.
Yet the biggest share is still held by the big cloud actors:
- Cloud platforms:
- Amazon Web Services: Glue, Athena.
- Google Cloud Platform: BigQuery.
- Azure Data Factory.
Around this time, AI was called Machine Learning. It was mostly statistics and math and wasn’t accessible through APIs.
I think at this time we went through the “slope of disillusionment” on big data technologies to reach the “plateau of stability.”
More details on the job Data Engineer created around 2015. Source: https://blog.det.life/the-history-of-data-engineering-1762b017541a.
Based on the progress in big data and other factors, AI was revolutionized. This piece explains the factors that made LLMs possible.
Personal View on the Current Situation (2020+)
Big Data and AI are related topics. AI is first a matter of data, but as it’s heavily productized, I don’t see why it would change the situation for big data. It is now mature, it works, but most companies don’t need it, especially not SMBs.
Big Data is disappearing from a commercial standpoint. Vendors don’t call it that anymore; it’s now only a tool and not a selling point.
Companies that started to make Big Data easy have shifted into making AI accessible.
AI has become LLMs and is API-ized, which is why it’s so easily adopted.