
May 10, 2025
This article is the second in a several-part series aimed at helping sales and marketing colleagues catch up on the data landscape and ecosystem. For each technology, I will highlight what existed before, who created it, and which pain points it was designed to solve.
Relational Database
Relational databases were defined in 1970 and started becoming commonly used in the 1980s. The main key point is that data is stored in tables with several columns, and tables have relationships between them. We use keys to link two tables and ensure their relationship exists. To make data retrieval easier, we use indexes, which under the hood are metadata tables.
| Creator | IBM |
| Reason | To organize and manage structured data efficiently |
| Use Case | Most commonly used, should be the default choice |
| Common Examples | Oracle, MySQL, PostgreSQL, SQLite, Snowflake |
Note that nowadays, most RDBMS (Relational Database Management Systems) are queried using SQL.
In the 1990s, object-oriented programming started growing, and while SQL remained widely used, it faced competition from ORM (Object-Relational Mapping). ORM abstracts the database and allows developers to access data as if it were simply objects in their code. SQL and ORM technologies are still commonly used today, each serving different contexts.
NoSQL and NewSQL
When the web grew larger and big tech companies started facing unprecedented challenges, RDBMS began to show their limitations. The opinionated design choices of traditional databases were sometimes unsuitable for the scale of the web.
NoSQL databases are often very fast, do not require fixed table schemas, avoid join operations by storing denormalized data, and are designed to scale horizontally.
In recent years, there has been a strong demand for massively distributed databases with high partition tolerance. However, according to the CAP theorem, it is impossible for a distributed system to simultaneously provide consistency, availability, and partition tolerance guarantees. A distributed system can satisfy any two of these guarantees at the same time, but not all three. For that reason, many NoSQL databases use what is called eventual consistency to provide both availability and partition tolerance guarantees with a reduced level of data consistency.
NewSQL is a class of modern relational databases that aims to provide the same scalable performance of NoSQL systems for online transaction processing (read-write) workloads while still using SQL and maintaining the ACID guarantees of a traditional database system.
Examples of Database Categories
Note that these different types of categories can be combined. For example, most data warehouses are distributed data warehouses.
In-Memory Database
An in-memory database is a database that primarily resides in main memory but is typically backed up by non-volatile computer data storage. Main memory databases are faster than disk databases and are often used where response time is critical, such as in telecommunications network equipment. The tradeoff is that you can’t store as much data in memory.
Data Warehouses
Data warehouses archive data from operational databases and often from external sources such as market research firms. The warehouse becomes the central source of data for use by managers and other end-users who may not have access to operational data. For example, sales data might be aggregated to weekly totals and converted from internal product codes to use UPCs so that they can be compared with ACNielsen data. Some basic and essential components of data warehousing include extracting, analyzing, mining, transforming, loading, and managing data to make them available for further use.
Distributed Databases
A distributed database is one in which both the data and the DBMS span multiple computers.
Document-Oriented Database
A document-oriented database is designed for storing, retrieving, and managing document-oriented or semi-structured information. Document-oriented databases are one of the main categories of NoSQL databases.
Embedded Database
An embedded database system is a DBMS tightly integrated with application software that requires access to stored data in such a way that the DBMS is hidden from the application’s end-users and requires little or no ongoing maintenance.
Federated Database System
A federated database system comprises several distinct databases, each with its own DBMS. It is handled as a single database by a federated database management system (FDBMS), which transparently integrates multiple autonomous DBMSs, possibly of different types (in which case it would also be a heterogeneous database system), and provides them with an integrated conceptual view.
Graph Database
A graph database is a kind of NoSQL database that uses graph structures with nodes, edges, and properties to represent and store information. General graph databases that can store any graph are distinct from specialized graph databases such as triplestores and network databases.
Key-Value Database
A key-value database is a type of non-relational database, also known as a NoSQL database, that uses a simple key-value method to store data. It stores data as a collection of key-value pairs in which a key serves as a unique identifier. Both keys and values can be anything, ranging from simple objects to complex compound objects. Key-value databases (or key-value stores) are highly partitionable and allow horizontal scaling at a level that other types of databases cannot achieve.
The strong point of this kind of database is the speed of data retrieval.
Column-Oriented Database
Tabular data is two-dimensional — data is modeled as rows and columns. However, computer systems represent data in a linear memory model, both in-disk and in-memory. Therefore, a table in a linear memory model requires mapping its two-dimensional scheme into a one-dimensional space. Data orientation refers to the decision taken in this mapping. There are two prominent mappings: row-oriented and column-oriented.
Being column-oriented is a common feature of most data warehouses because it greatly improves scalability.
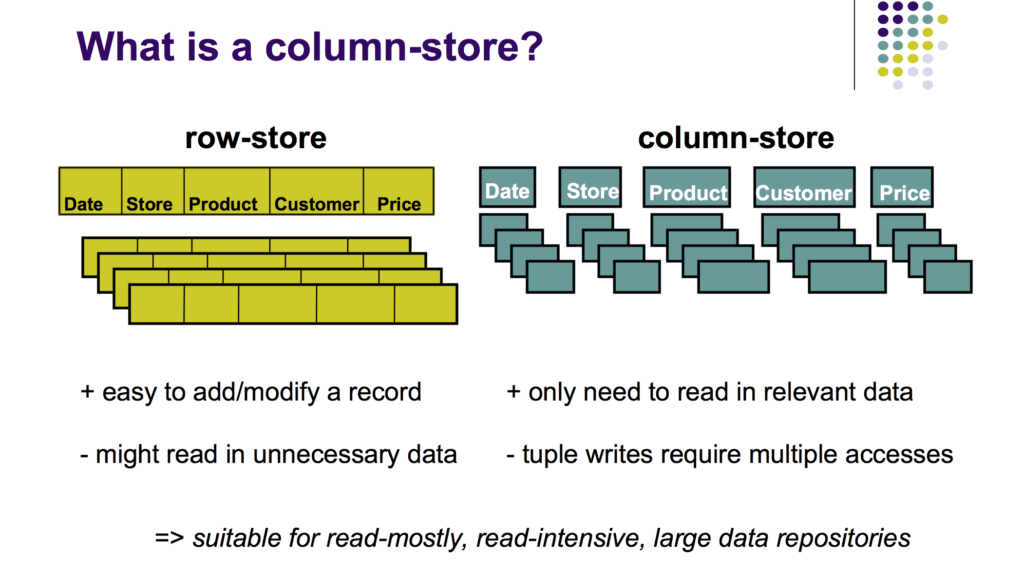 Difference between column storage and standard storage
Difference between column storage and standard storage
Vector Database
A vector database, vector store, or vector search engine is a database that can store vectors (fixed-length lists of numbers) along with other data items. Vector databases typically implement one or more Approximate Nearest Neighbor algorithms, so that one can search the database with a query vector to retrieve the closest matching database records.
Vector databases can be used for similarity search, semantic search, multi-modal search, recommendation engines, large language models (LLMs), object detection, etc.
Vector databases are also often used to implement retrieval-augmented generation (RAG), a method to improve domain-specific responses of large language models.
Operational Database
Operational databases store detailed data about the operations of an organization. They typically process relatively high volumes of updates using transactions. Examples include customer databases that record contact, credit, and demographic information about a business’s customers, personnel databases that hold information such as salary, benefits, and skills data about employees, enterprise resource planning systems that record details about product components, parts inventory, and financial databases that keep track of the organization’s money, accounting, and financial dealings.
Real-Time Database
Real-time databases process transactions fast enough for the result to come back and be acted on right away.
Spatial Database
A spatial database can store data with multidimensional features. Queries on such data include location-based queries, like “Where is the closest hotel in my area?”
Temporal Database
A temporal database has built-in time aspects, for example, a temporal data model and a temporal version of SQL. More specifically, the temporal aspects usually include valid-time and transaction-time.
Glossary
ACID
ACID (atomicity, consistency, isolation, durability) is a set of properties of database transactions intended to guarantee data validity despite errors, power failures, and other mishaps. In the context of databases, a sequence of database operations that satisfies the ACID properties (which can be perceived as a single logical operation on the data) is called a transaction.
OLAP
Online Analytical Processing: Databases configured for OLAP use a multidimensional data model, allowing for complex analytical and ad hoc queries with rapid execution time.
OLAP is used to help you understand your business.
OLTP
Online Transaction Processing (OLTP) is a type of database system used in transaction-oriented applications, such as many operational systems. “Online” refers to the fact that such systems are expected to respond to user requests and process them in real-time (process transactions).
OLTP is used directly for your business.